2月6日消息 近日,国外SEO从业者Eli Schwartz分享了他使用Splunk的几个心得。以下为Eli Schwarz(下文中的“我”)分享的经验:
想必每个对SEO技术感兴趣的站长都希望能够从更深层次了解网站架构、以及谷歌搜索引擎的排名规则等。从我这些年研究SEO技术的经验来看,深入分析网站访问日志能够让我更了解搜索引擎是如何“看待”网站的,而在众多网站分析工具中,Splunk无疑是最让我放心、也是最实用的一款。
注:Splunk是机器数据的引擎。可用于收集、索引和利用所有应用程序、服务器和设备(物理、虚拟和云中)生成的快速移动型计算机数据 。
1、监测网站URL是否已被谷歌爬虫抓取(百度蜘蛛、雅虎爬虫亦可监测)
当网站生成了一个新的页面,站长们最关心的自然是页面的收录问题。如果以快照作为指标,或许得在谷歌爬虫抓取后的几天(甚至几个星期)才能确定是否已被收录。要快点儿的话,可以直接在搜索引擎中搜索相关页面的标题。
而最行之有效的便是查看网站日志,便可确定网页是否已被谷歌爬虫抓取。这就该用到Splunk了。
具体步骤:
1、首先选择要查询的时间段。时间段越短,响应速度自然越快,所以尽可能缩短查询的时间差。
2、在查询框中输入以下查询语句:
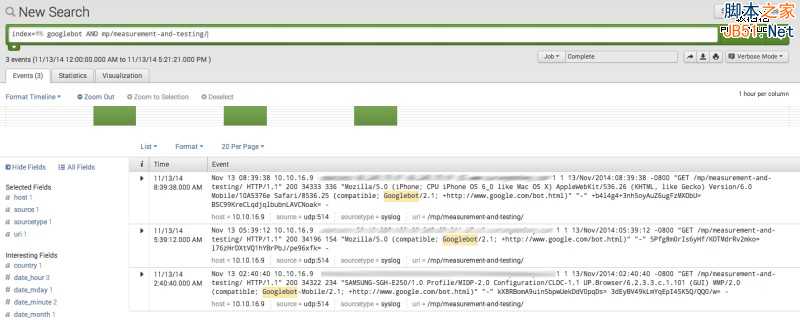
Index = {the name of your index} url stub AND googlebot
比如:如果你索引名是“Primary”,URL是“free-trial.html”,则查询语句为:
Index=primary free-trial.html AND googlebot
1、查看日志
2、查找404页面
404页面是一种很招人烦的东西,98%的访客在看到404页面时,往往都会直接关闭页面。这样一来,你的网站不仅损失了一次展示内容或产品的几乎,用户还默默的在心里给了你个差评。你:以后还来我们网站吗?用户:呵呵。
对于404页面,你可以选择使用ScreamingFrog之类的工具来查找修复。但是在失效页面数量太多的情况下,你就该事实日志解析了。通过日志解析,你可以找出那些最多人访问的404页面,有选择的来修复页面、或是做跳转。
设置Splunk来查找404页面:
1、首先选择查找时间差,我通常将其设为30天,你们可以按需随意设置。
2、在查询框中输入以下查询语句:
Index = {the name of your index} status = 404 | top limit = 50 uri
限制数量可自行确定,我比较喜欢定为50条URL。查询语句执行完成后,点击Statistics选项,便可在列表中找出访客最多的404页面们。
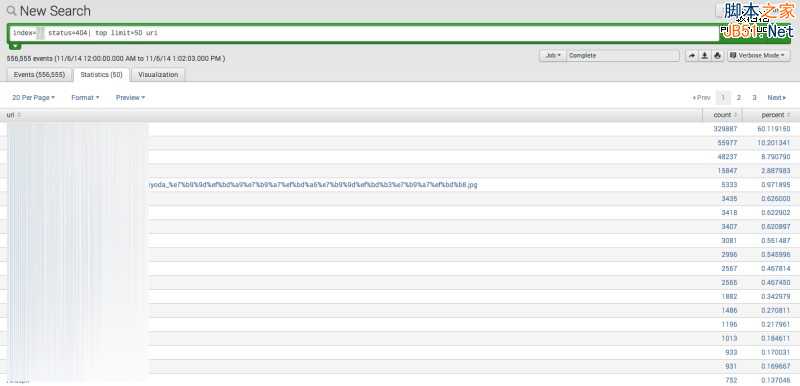
2、查找404页面
3、查找设置过302跳转的页面
不同于301跳转,302跳转属于暂时重定向。不过在很多链接价值测试中,302都能通过测试,而且也有排名。但由于前些年,不少黑帽SEO通过这项技术来获取排名,如今很多搜索引擎都加大了对其的打击力度。因而302跳转只能用于那些只需做暂时跳转的页面。
通过Splunk查找302跳转页面的步骤:
1、同样也是先选择查找时间段,可按需设置,我喜欢将其设为30天。
2、输入如下查询语句:
Index = {the name of your index} status = 302 | top limit = 50 uri
跟查找404页面一样,可按需设置。

3、查找302跳转页面
4、统计每天被谷歌搜索引擎抓取的页面
如果你有用过谷歌管理员工具,那么你对谷歌抓取URL的展示页面一定不陌生。但这些数据是否准确,你得查看网站日志才能确定。
使用Splunk查询每日抓取的URL步骤:
1、同样也是选取时间,我还是喜欢设为30天(如果数据较多可以7天为单位)。
2、输入查询语句:
index ={name of your index} googlebot | timechart count by day
查询语句执行完后,点击Statistics选项,则会看到谷歌爬虫每天抓取的页面数据。也可点击“visualization”选项查看变化详情。
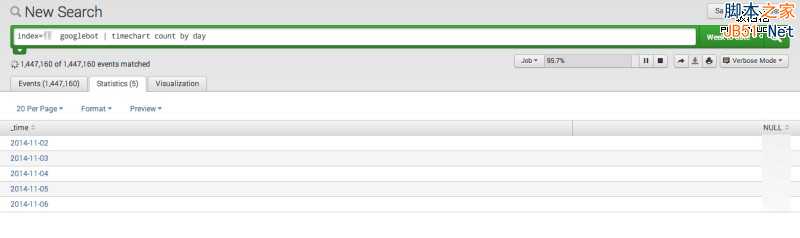
4、谷歌爬虫每日抓取页面
5、统计谷歌移动端爬虫每日抓取页面
随着移动互联网的发展,移动搜索也愈发重要。如果想知道谷歌移动爬虫每天抓取的URL数量,就无法使用谷歌管理员工具了。那么,就只能通过网站访问日志来查看该数据。
下面以iPhone为例,使用Splunk查询:
1、同样也是选取时间,我还是喜欢设为30天(如果数据较多可以7天为单位)。
2、输入以下查询语句:
index ={name of your index} googlebot AND iphone | timechart count by day
语句执行完毕后,点击Statistics选项,便可得出所需数据,与PC端一样,也可以在“visualization”选项中查看更多详情。
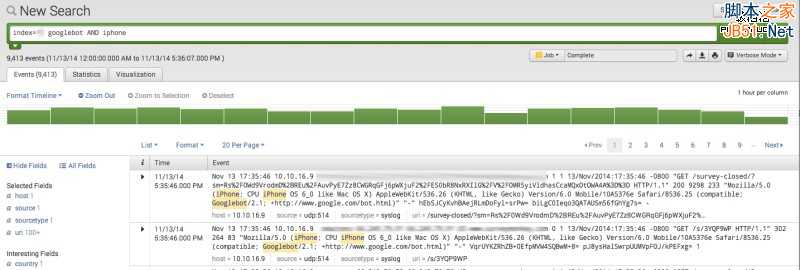
5、谷歌移动爬虫每日抓取页面
6、找出浪费爬虫抓取量的垃圾页面
站长们都知道,搜索引擎对每个网站的抓取数量都有一定的限制,网站的PR或权重不同,抓取“限额”也各异。所以,如果网站中的垃圾页面被抓取,那么高质页面则可能会失去被抓取的机会。
如果不清楚谷歌爬虫的爬行路径,则无法知晓谷歌抓取限额的利用率。这时候,就需要使用Splunk来检测了。
步骤如下:
1、选择时间段,可随意选取,最好选择多个进行对比。
2、输入以下查询语句:
index={name of your index} googlebot uri_stem=”*”| top limit=20 uri
限制数量可随意选取,但20条是比较好管理的。与之前一样,执行完语句后,点击statistic选项,而后便可在列表中找出你觉得应该移除的页面,在robots.txt文件中将其屏蔽。
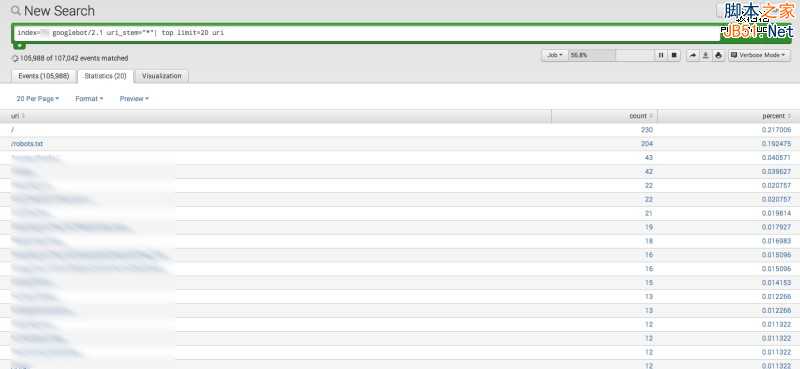
6、筛选需屏蔽页面
7、500错误页面
当服务器无法完成HTTP请求时,则会返回500错误页面。很多时候,500错误对SEO工作都存在一定的负面影响。其实,在500错误影响到搜索排名时,谷歌便会通过管理员工具向站长发送请求中断信息,不过这类信息通常要24小时后才能接收到。
除了影响搜索引擎排名外,500错误页面也会降低网站的用户体验度。而加入Splunk工具的Enterprise计划则可实时监控500错误。
步骤如下:
1、搜索如下查询语句:
index={name of your index} AND “status=5*”
2、点击“Save As”然后在下拉菜单中选择“Alert”。
3、命名Alert。
4、将Alert的状态改为“Real Time”。
5、点击“Next”。
6、在下个页面,会出现“Send Email”选项。
7、在输入框中输入邮件,然后点击“Save”。
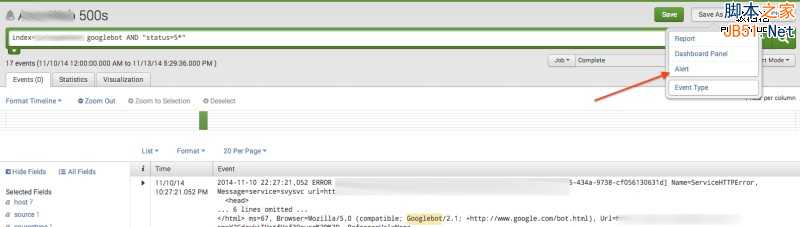
7、实时监控500页面
总结
Splunk可以用于多种SEO工作,可以给工作带来很大的便利性。如果还没用过的站长们,不妨尝试下哦!
SEO实战,Splunk,析网站
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]